02 · Motivation
From a debating crowd to a single thinker
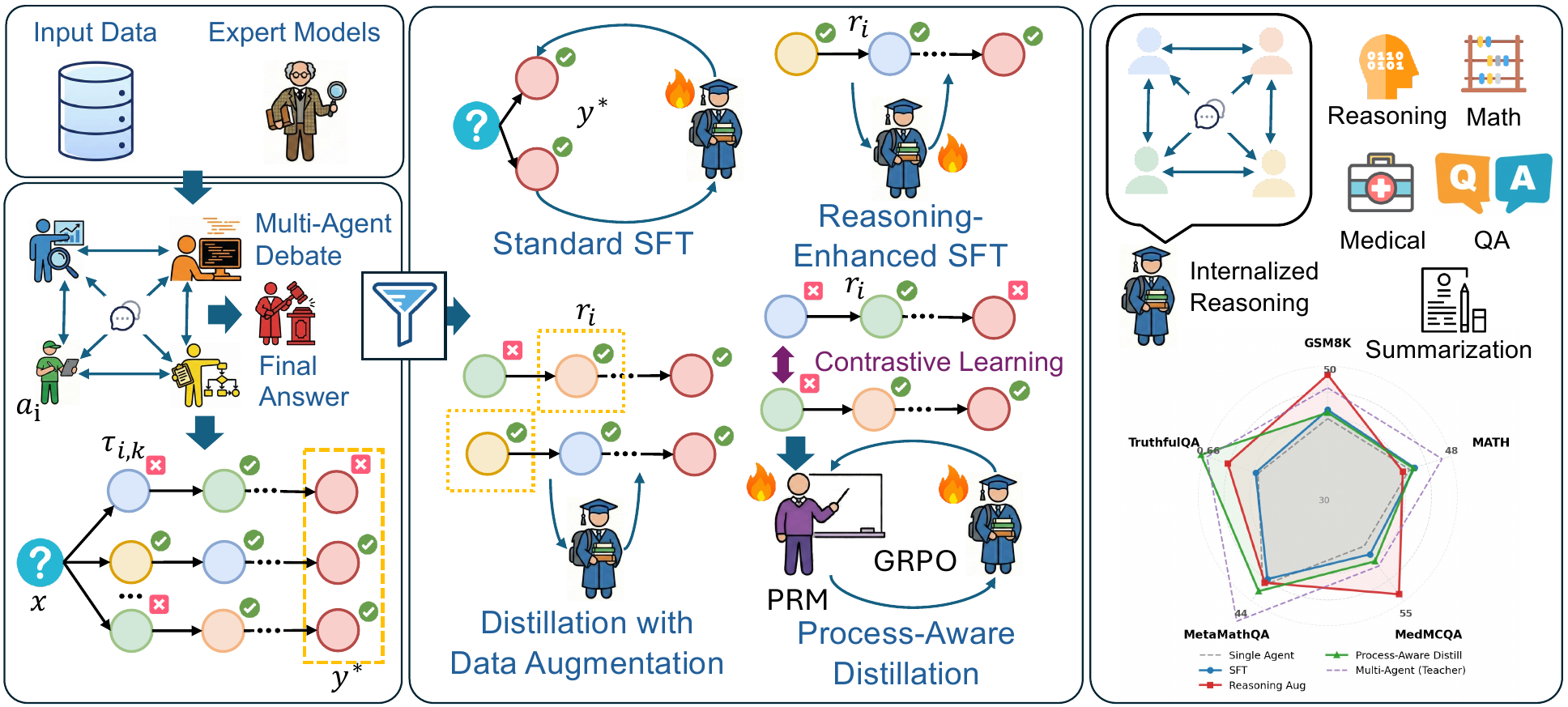
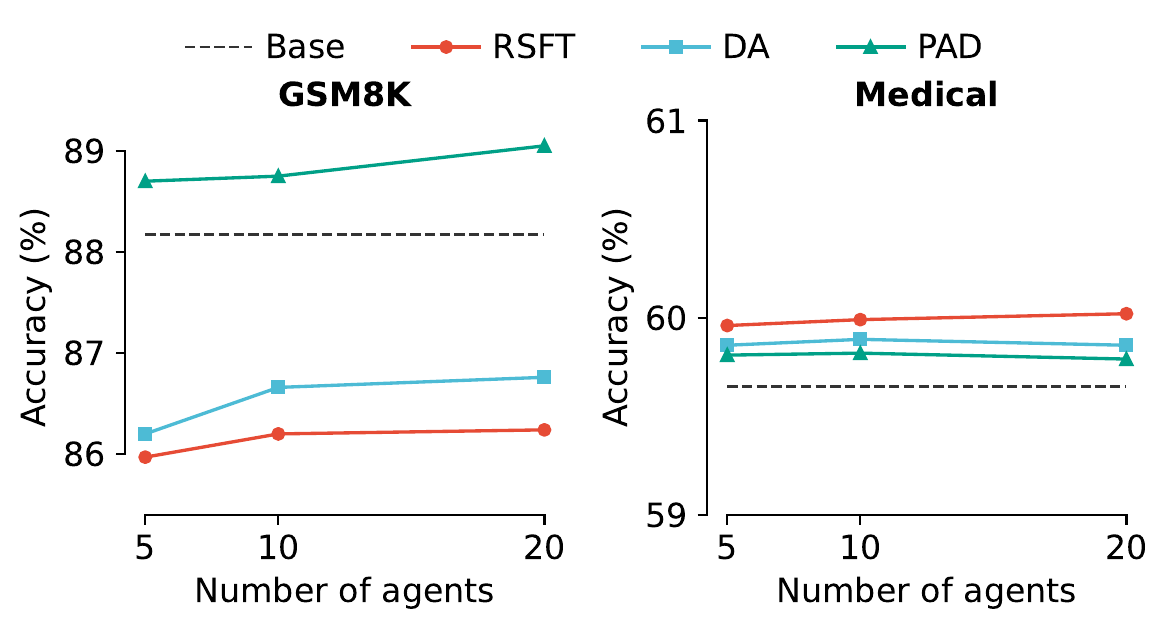
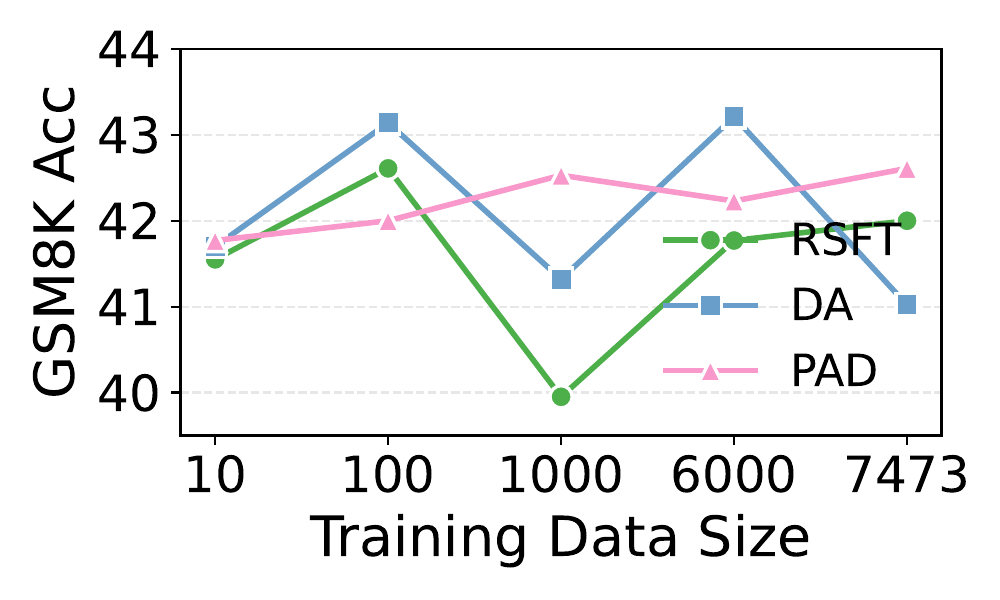
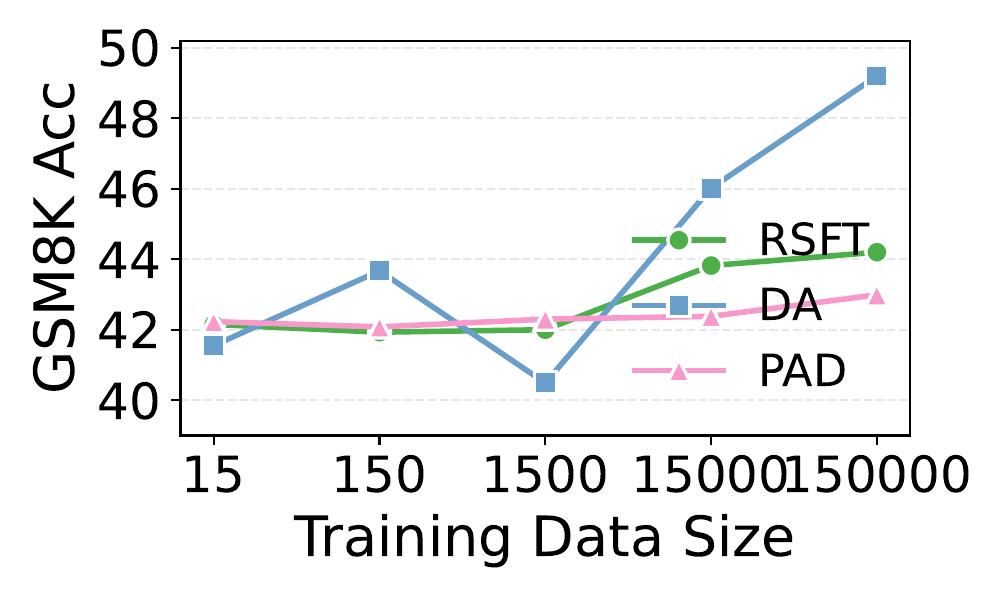
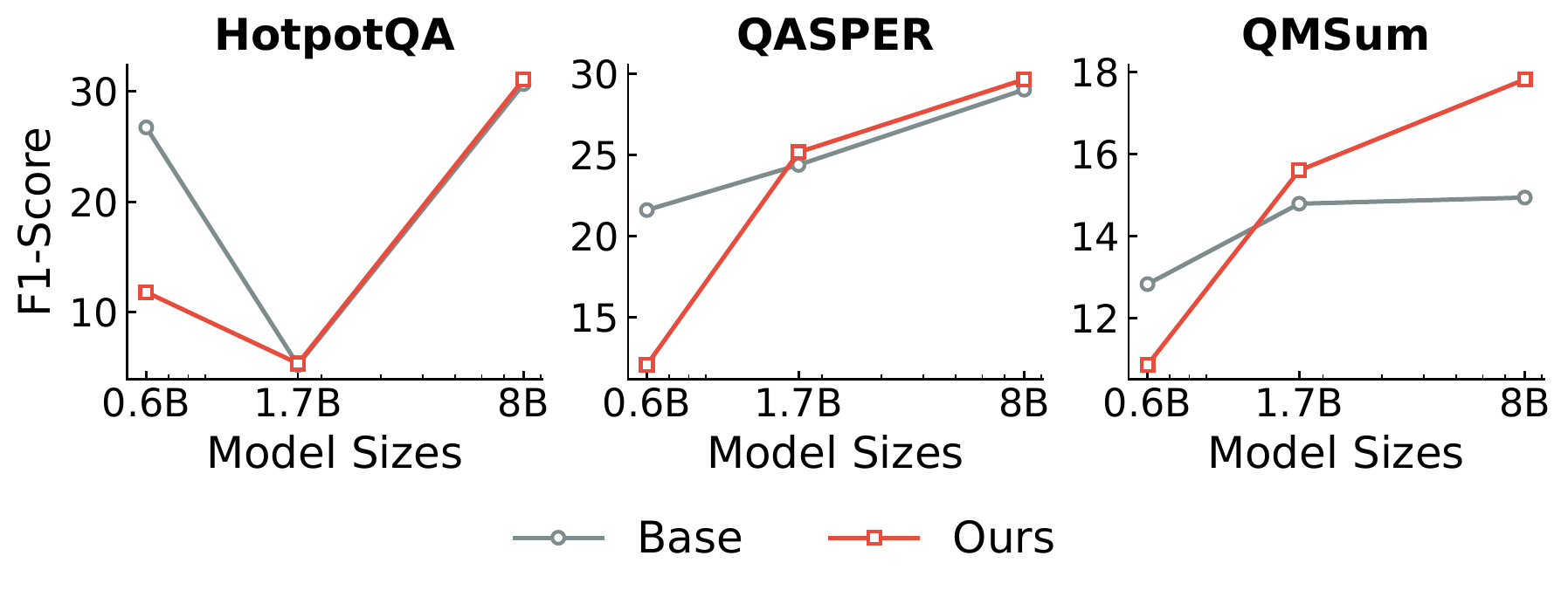
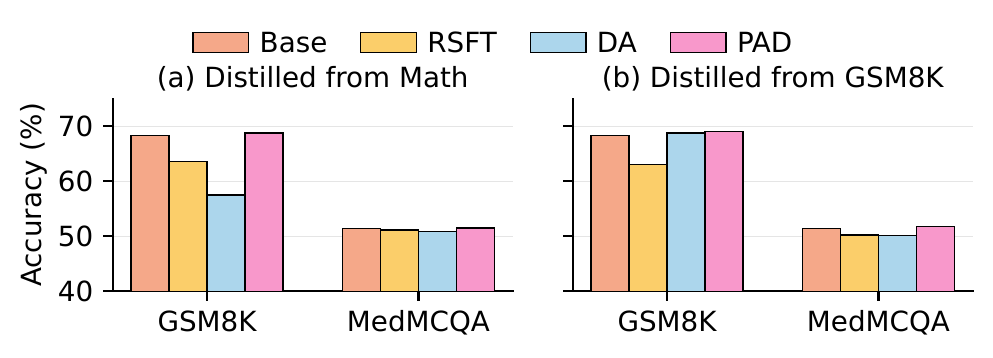
Multi-agent debate produces strong reasoning but is slow and brittle. AgentArk compresses the dynamics of an agent ensemble into the weights of one model — preserving the collective behavior at single-agent inference cost.
AgentArk distills the reasoning capability of a multi-agent system into a single agent, so that one unit imitates the collective thinking process with boosted performance and a fraction of the inference cost.